 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitLM: Unlocking Multi-Token Language Generation with Bitwise Continuous Diffusion
May 12, 2026Autoregressive language models generate text one token at a time, yet natural language is inherently structured in multi-token units, including phrases, n-grams, and collocations that carry meaning jointly. This one-token bottleneck limits both the expressiveness of the model during pre-training and its throughput at inference time. Existing remedies such as speculative decoding or diffusion-based language models either leave the underlying bottleneck intact or sacrifice the causal structure essential to language modeling. We propose BitLM, a language model that represents each token as a fixed-length binary code and employs a lightweight diffusion head to denoise multiple tokens in parallel within each block. Crucially, BitLM preserves left-to-right causal attention across blocks while making joint lexical decisions within each block, combining the reliability of autoregressive modeling with the parallelism of iterative refinement. By replacing the large-vocabulary softmax with bitwise denoising, BitLM reframes token generation as iterative commitment in a compact binary space, enabling more efficient pre-training and substantially faster inference without altering the causal foundation that makes language models effective. Our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement but an interface choice, and that changing it can yield a stronger and faster language model. We hope BitLM points toward a promising direction for next-generation language model architectures.
ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Mar 31, 2026Multimodal Large Language Models (MLLMs) achieve stronger visual understanding by scaling input fidelity, yet the resulting visual token growth makes jointly sustaining high spatial resolution and long temporal context prohibitive. We argue that the bottleneck lies not in how post-encoding representations are compressed but in the volume of pixels the encoder receives, and address it with ResAdapt, an Input-side adaptation framework that learns how much visual budget each frame should receive before encoding. ResAdapt couples a lightweight Allocator with an unchanged MLLM backbone, so the backbone retains its native visual-token interface while receiving an operator-transformed input. We formulate allocation as a contextual bandit and train the Allocator with Cost-Aware Policy Optimization (CAPO), which converts sparse rollout feedback into a stable accuracy-cost learning signal. Across budget-controlled video QA, temporal grounding, and image reasoning tasks, ResAdapt improves low-budget operating points and often lies on or near the efficiency-accuracy frontier, with the clearest gains on reasoning-intensive benchmarks under aggressive compression. Notably, ResAdapt supports up to 16x more frames at the same visual budget while delivering over 15% performance gain. Code is available at https://github.com/Xnhyacinth/ResAdapt.
CAMEL: Confidence-Gated Reflection for Reward Modeling
Feb 24, 2026Reward models play a fundamental role in aligning large language models with human preferences. Existing methods predominantly follow two paradigms: scalar discriminative preference models, which are efficient but lack interpretability, and generative judging models, which offer richer reasoning at the cost of higher computational overhead. We observe that the log-probability margin between verdict tokens strongly correlates with prediction correctness, providing a reliable proxy for instance difficulty without additional inference cost. Building on this insight, we propose CAMEL, a confidence-gated reflection framework that performs a lightweight single-token preference decision first and selectively invokes reflection only for low-confidence instances. To induce effective self-correction, we train the model via reinforcement learning with counterfactual prefix augmentation, which exposes the model to diverse initial verdicts and encourages genuine revision. Empirically, CAMEL achieves state-of-the-art performance on three widely used reward-model benchmarks with 82.9% average accuracy, surpassing the best prior model by 3.2% and outperforming 70B-parameter models using only 14B parameters, while establishing a strictly better accuracy-efficiency Pareto frontier.
UniWeTok: An Unified Binary Tokenizer with Codebook Size $\mathit{2^{128}}$ for Unified Multimodal Large Language Model
Feb 15, 2026Unified Multimodal Large Language Models (MLLMs) require a visual representation that simultaneously supports high-fidelity reconstruction, complex semantic extraction, and generative suitability. However, existing visual tokenizers typically struggle to satisfy these conflicting objectives within a single framework. In this paper, we introduce UniWeTok, a unified discrete tokenizer designed to bridge this gap using a massive binary codebook ($\mathit{2^{128}}$). For training framework, we introduce Pre-Post Distillation and a Generative-Aware Prior to enhance the semantic extraction and generative prior of the discrete tokens. In terms of model architecture, we propose a convolution-attention hybrid architecture with the SigLu activation function. SigLu activation not only bounds the encoder output and stabilizes the semantic distillation process but also effectively addresses the optimization conflict between token entropy loss and commitment loss. We further propose a three-stage training framework designed to enhance UniWeTok's adaptability cross various image resolutions and perception-sensitive scenarios, such as those involving human faces and textual content. On ImageNet, UniWeTok achieves state-of-the-art image generation performance (FID: UniWeTok 1.38 vs. REPA 1.42) while requiring a remarkably low training compute (Training Tokens: UniWeTok 33B vs. REPA 262B). On general-domain, UniWeTok demonstrates highly competitive capabilities across a broad range of tasks, including multimodal understanding, image generation (DPG Score: UniWeTok 86.63 vs. FLUX.1 [Dev] 83.84), and editing (GEdit Overall Score: UniWeTok 5.09 vs. OmniGen 5.06). We release code and models to facilitate community exploration of unified tokenizer and MLLM.
WideSeek: Advancing Wide Research via Multi-Agent Scaling
Feb 02, 2026Search intelligence is evolving from Deep Research to Wide Research, a paradigm essential for retrieving and synthesizing comprehensive information under complex constraints in parallel. However, progress in this field is impeded by the lack of dedicated benchmarks and optimization methodologies for search breadth. To address these challenges, we take a deep dive into Wide Research from two perspectives: Data Pipeline and Agent Optimization. First, we produce WideSeekBench, a General Broad Information Seeking (GBIS) benchmark constructed via a rigorous multi-phase data pipeline to ensure diversity across the target information volume, logical constraints, and domains. Second, we introduce WideSeek, a dynamic hierarchical multi-agent architecture that can autonomously fork parallel sub-agents based on task requirements. Furthermore, we design a unified training framework that linearizes multi-agent trajectories and optimizes the system using end-to-end RL. Experimental results demonstrate the effectiveness of WideSeek and multi-agent RL, highlighting that scaling the number of agents is a promising direction for advancing the Wide Research paradigm.
Learning from Next-Frame Prediction: Autoregressive Video Modeling Encodes Effective Representations
Dec 24, 2025



Recent advances in pretraining general foundation models have significantly improved performance across diverse downstream tasks. While autoregressive (AR) generative models like GPT have revolutionized NLP, most visual generative pretraining methods still rely on BERT-style masked modeling, which often disregards the temporal information essential for video analysis. The few existing autoregressive visual pretraining methods suffer from issues such as inaccurate semantic localization and poor generation quality, leading to poor semantics. In this work, we propose NExT-Vid, a novel autoregressive visual generative pretraining framework that utilizes masked next-frame prediction to jointly model images and videos. NExT-Vid introduces a context-isolated autoregressive predictor to decouple semantic representation from target decoding, and a conditioned flow-matching decoder to enhance generation quality and diversity. Through context-isolated flow-matching pretraining, our approach achieves strong representations. Extensive experiments on large-scale pretrained models demonstrate that our proposed method consistently outperforms previous generative pretraining methods for visual representation learning via attentive probing in downstream classification.
Broadband Near-Infrared Compressive Spectral Imaging System with Reflective Structure
Aug 20, 2025



Near-infrared (NIR) hyperspectral imaging has become a critical tool in modern analytical science. However, conventional NIR hyperspectral imaging systems face challenges including high cost, bulky instrumentation, and inefficient data collection. In this work, we demonstrate a broadband NIR compressive spectral imaging system that is capable of capturing hyperspectral data covering a broad spectral bandwidth ranging from 700 to 1600 nm. By segmenting wavelengths and designing specialized optical components, our design overcomes hardware spectral limitations to capture broadband data, while the reflective optical structure makes the system compact. This approach provides a novel technical solution for NIR hyperspectral imaging.
Integrated Snapshot Near-infrared Hypersepctral Imaging Framework with Diffractive Optics
Aug 20, 2025



We propose an integrated snapshot near-infrared hyperspectral imaging framework that combines designed DOE with NIRSA-Net. The results demonstrate near-infrared spectral imaging at 700-1000nm with 10nm resolution while achieving improvement of PSNR 1.47dB and SSIM 0.006.
InstanceBEV: Unifying Instance and BEV Representation for Global Modeling
May 20, 2025
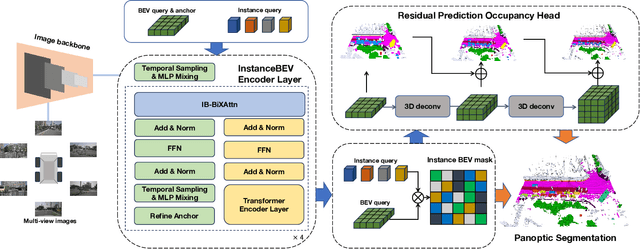

Occupancy Grid Maps are widely used in navigation for their ability to represent 3D space occupancy. However, existing methods that utilize multi-view cameras to construct Occupancy Networks for perception modeling suffer from cubic growth in data complexity. Adopting a Bird's-Eye View (BEV) perspective offers a more practical solution for autonomous driving, as it provides higher semantic density and mitigates complex object occlusions. Nonetheless, BEV-based approaches still require extensive engineering optimizations to enable efficient large-scale global modeling. To address this challenge, we propose InstanceBEV, the first method to introduce instance-level dimensionality reduction for BEV, enabling global modeling with transformers without relying on sparsification or acceleration operators. Different from other BEV methods, our approach directly employs transformers to aggregate global features. Compared to 3D object detection models, our method samples global feature maps into 3D space. Experiments on OpenOcc-NuScenes dataset show that InstanceBEV achieves state-of-the-art performance while maintaining a simple, efficient framework without requiring additional optimizations.
Efficient training for large-scale optical neural network using an evolutionary strategy and attention pruning
May 19, 2025MZI-based block optical neural networks (BONNs), which can achieve large-scale network models, have increasingly drawn attentions. However, the robustness of the current training algorithm is not high enough. Moreover, large-scale BONNs usually contain numerous trainable parameters, resulting in expensive computation and power consumption. In this article, by pruning matrix blocks and directly optimizing the individuals in population, we propose an on-chip covariance matrix adaptation evolution strategy and attention-based pruning (CAP) algorithm for large-scale BONNs. The calculated results demonstrate that the CAP algorithm can prune 60% and 80% of the parameters for MNIST and Fashion-MNIST datasets, respectively, while only degrades the performance by 3.289% and 4.693%. Considering the influence of dynamic noise in phase shifters, our proposed CAP algorithm (performance degradation of 22.327% for MNIST dataset and 24.019% for Fashion-MNIST dataset utilizing a poor fabricated chip and electrical control with a standard deviation of 0.5) exhibits strongest robustness compared with both our previously reported block adjoint training algorithm (43.963% and 41.074%) and the covariance matrix adaptation evolution strategy (25.757% and 32.871%), respectively. Moreover, when 60% of the parameters are pruned, the CAP algorithm realizes 88.5% accuracy in experiment for the simplified MNIST dataset, which is similar to the simulation result without noise (92.1%). Additionally, we simulationally and experimentally demonstrate that using MZIs with only internal phase shifters to construct BONNs is an efficient way to reduce both the system area and the required trainable parameters. Notably, our proposed CAP algorithm show excellent potential for larger-scale network models and more complex tasks.